scrapy时Python界非常著名的爬虫框架,但是一遇到分布式应用的话就会捉襟见肘了,scrapy-redis就是为了解决这一痛点诞生的,他把start_urls从中剥离出来,改为从redis中读取,多个应用读取同一个redis,从而实现了分布式爬虫.
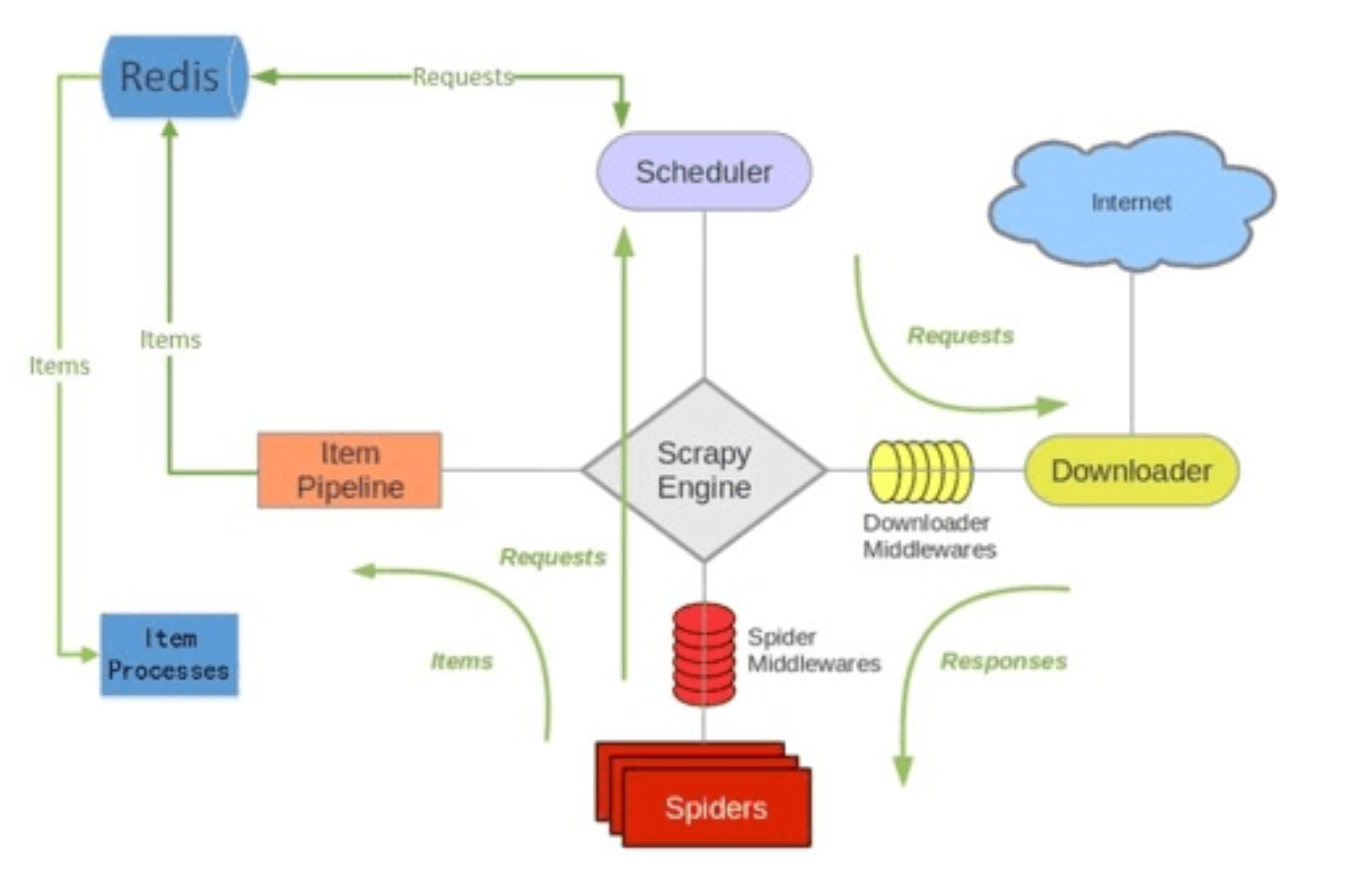
本篇博客暂时不说scrapy-redis如何做到分布式的, 先来看一下这个框架时如何做到url去重的,源码在下面
scrapy-redis自带的过滤器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
|
# TODO: Rename class to RedisDupeFilter.
class RFPDupeFilter(BaseDupeFilter):
"""Redis-based request duplicates filter.
This class can also be used with default Scrapy's scheduler.
"""
logger = logger
def __init__(self, server, key, debug=False):
"""Initialize the duplicates filter.
Parameters
----------
server : redis.StrictRedis
The redis server instance.
key : str
Redis key Where to store fingerprints.
debug : bool, optional
Whether to log filtered requests.
"""
self.server = server
self.key = key
self.debug = debug
self.logdupes = True
@classmethod
def from_settings(cls, settings):
"""Returns an instance from given settings.
This uses by default the key ``dupefilter:<timestamp>``. When using the
``scrapy_redis.scheduler.Scheduler`` class, this method is not used as
it needs to pass the spider name in the key.
Parameters
----------
settings : scrapy.settings.Settings
Returns
-------
RFPDupeFilter
A RFPDupeFilter instance.
"""
server = get_redis_from_settings(settings)
# XXX: This creates one-time key. needed to support to use this
# class as standalone dupefilter with scrapy's default scheduler
# if scrapy passes spider on open() method this wouldn't be needed
# TODO: Use SCRAPY_JOB env as default and fallback to timestamp.
key = defaults.DUPEFILTER_KEY % {'timestamp': int(time.time())}
debug = settings.getbool('DUPEFILTER_DEBUG')
return cls(server, key=key, debug=debug)
@classmethod
def from_crawler(cls, crawler):
"""Returns instance from crawler.
Parameters
----------
crawler : scrapy.crawler.Crawler
Returns
-------
RFPDupeFilter
Instance of RFPDupeFilter.
"""
return cls.from_settings(crawler.settings)
def request_seen(self, request):
"""Returns True if request was already seen.
Parameters
----------
request : scrapy.http.Request
Returns
-------
bool
"""
fp = self.request_fingerprint(request)
# This returns the number of values added, zero if already exists.
added = self.server.sadd(self.key, fp)
return added == 0
def request_fingerprint(self, request):
"""Returns a fingerprint for a given request.
Parameters
----------
request : scrapy.http.Request
Returns
-------
str
"""
return request_fingerprint(request)
def close(self, reason=''):
"""Delete data on close. Called by Scrapy's scheduler.
Parameters
----------
reason : str, optional
"""
self.clear()
def clear(self):
"""Clears fingerprints data."""
self.server.delete(self.key)
def log(self, request, spider):
"""Logs given request.
Parameters
----------
request : scrapy.http.Request
spider : scrapy.spiders.Spider
"""
if self.debug:
msg = "Filtered duplicate request: %(request)s"
self.logger.debug(msg, {'request': request}, extra={'spider': spider})
elif self.logdupes:
msg = ("Filtered duplicate request %(request)s"
" - no more duplicates will be shown"
" (see DUPEFILTER_DEBUG to show all duplicates)")
self.logger.debug(msg, {'request': request}, extra={'spider': spider})
self.logdupes = False
|
要实现去重最主要的两个函数就是request_seen,request_fingerprint.他们做个很简单的事就是获取当前请求的指纹,然后把指纹加入到redis的一个set中.redis中的set数据结构特点是无序,不可重复,无论数据有多少插入删除的时间复杂度为O(1).至于请求的指纹他们时调用requests库的方法实现的.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
_fingerprint_cache = weakref.WeakKeyDictionary()
def request_fingerprint(request, include_headers=None):
"""
Return the request fingerprint.
The request fingerprint is a hash that uniquely identifies the resource the
request points to. For example, take the following two urls:
http://www.example.com/query?id=111&cat=222
http://www.example.com/query?cat=222&id=111
Even though those are two different URLs both point to the same resource
and are equivalent (ie. they should return the same response).
Another example are cookies used to store session ids. Suppose the
following page is only accesible to authenticated users:
http://www.example.com/members/offers.html
Lot of sites use a cookie to store the session id, which adds a random
component to the HTTP Request and thus should be ignored when calculating
the fingerprint.
For this reason, request headers are ignored by default when calculating
the fingeprint. If you want to include specific headers use the
include_headers argument, which is a list of Request headers to include.
"""
if include_headers:
include_headers = tuple(to_bytes(h.lower())
for h in sorted(include_headers))
cache = _fingerprint_cache.setdefault(request, {})
if include_headers not in cache:
fp = hashlib.sha1()
fp.update(to_bytes(request.method))
fp.update(to_bytes(canonicalize_url(request.url)))
fp.update(request.body or b'')
if include_headers:
for hdr in include_headers:
if hdr in request.headers:
fp.update(hdr)
for v in request.headers.getlist(hdr):
fp.update(v)
cache[include_headers] = fp.hexdigest()
return cache[include_headers]
|
正如上面的注释所说,url的query会被忽略,因为他们指向的是同一网络资源.并且会默认忽略请求头里的东西来生成唯一指纹,因为很多站点拿请求头存一些类似于session的东西,但是开发者可以自己指定请求头.
fp哈希值里最多会包含如下信息:
- 请求方法
- 请求url
- 请求body
- headers里的hdr
使用这么多东西来确保请求的唯一性,好啦源码分析结束~~